1.经验:
在关系型数据库中,使用insert,update的情况是很多的,但是在大数据中,比如hive中,这种使用情况是很少的,基本上都用用load,把一个文件和一批文件load进hive表里,其实就是把这些文件load到hdfs中去。
2.LOAD:
LOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 …)]
LOCAL:表示的是本地,就是Linux上。如果不带LOCAL,相当于这个数据在hdfs上。
‘filepath’ : 表示指向你数据所在的一个路径。
OVERWRITE: 表示将之前的数据覆盖。
INTO TABLE:表示追加。
PARTITION :表示分区。
首先我们先创建一张表:
create table dept(
deptno int,
dname string,
location string
) row format delimited fields terminated by ‘\t’;
LOAD DATA LOCAL INPATH ‘/home/hadoop/data/dept.txt’ OVERWRITE INTO TABLE dept;(覆盖)
LOAD DATA LOCAL INPATH ‘/home/hadoop/data/dept.txt’ INTO TABLE dept;(追加)

从上图就可以看出OVERWRITE和 INTO TABLE的区别。
下面我们试一下从hdfs上加载数据到表里:
首先现在hdfs上创建一个目录,将文件放到目录下:

然后加载数据到dept表里:
LOAD DATA INPATH ‘/hive/dept/dept.txt’ OVERWRITE INTO TABLE dept;(没有LOCAL,表示从hdfs加载数据)
 这个时候到hdfs上看,发现文件没有了,
这个时候到hdfs上看,发现文件没有了, (它被移到dept这张表默认的hdfs的路径下了,这里是:hdfs://10-9-140-90:9000/user/hive/warehouse/d6_hive.db/dept)
(它被移到dept这张表默认的hdfs的路径下了,这里是:hdfs://10-9-140-90:9000/user/hive/warehouse/d6_hive.db/dept)下面我们将hive上查询出的结果写到本地(或者hdfs)文件系统上:
INSERT OVERWRITE LOCAL DIRECTORY ‘/home/hadoop/data/emptmp’
row format delimited fields terminated by ‘,’
SELECT empno,ename FROM emp;


写到hdfs上(把LOCAL去掉即可):
INSERT OVERWRITE DIRECTORY ‘/emptmp’
row format delimited fields terminated by ‘,’
SELECT empno,ename FROM emp;
INSERT语法方面是支持的,但是生产中我们很少很少用,会产生很多小文件。 hive -e 和hive -f的使用:
hive -e “select * from d6_test.emp” 或者
hive -e “use d6_test; select * from emp”,一般生产中写到脚本中,通过执行脚本,执行。 这种不进入hive就可以查询表的情况适合?适合写脚本,比如写一个脚本,在里面写hive语句:
这种不进入hive就可以查询表的情况适合?适合写脚本,比如写一个脚本,在里面写hive语句:
 hive -f 的使用:
hive -f 的使用:
将sql写到文件中,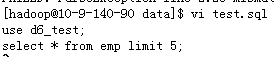

然后如果每天需要执行一次,crontab -e ,添加一个计划即可。
hive里的清屏:!clear
常用sql语法:
where = > >= < <=
limit
between and []
(not) in
聚合函数:max min sum count avg 多进一出 每个部门的平均工资
每个部门的平均工资
1) 拿到每个部分的信息
2) 在1)的基础之上求平均工资 select deptno,avg(sal) from emp group by deptno;
select deptno,avg(sal) from emp group by deptno;
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal >=2000;
case when then 常用于报表中:
select ename, sal,
case
when sal > 1 and sal <=1000 then ‘lower’
when sal > 1000 and sal <=2000 then ‘middle’
when sal > 2000 and sal <=3000 then ‘high’
else ‘highest’ end
from emp;
函数 build-in(内置的函数:hive本身自带的函数) (UDFs外置的函数:自定义的函数)
看官网,在这里面可以找到相应的函数以及使用说明:
在hive里面使用: show functions; 可以看到hive所有内置的函数:
用 desc function 函数名称; 可以查看这个函数的相关说明:
 (官网)
(官网)
时间相关的函数:
当前时间:current_date
当前具体时间:current_timestamp
时间戳:unix_timestamp()(经常用)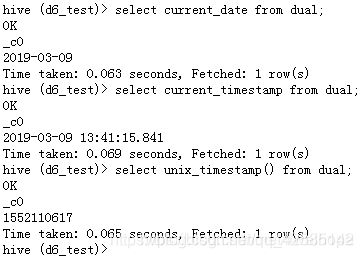
 nix_timestamp()时间戳可以传入参数进行转换。比如
nix_timestamp()时间戳可以传入参数进行转换。比如
select unix_timestamp(‘2019-03-09 13:41:15.841’, ‘yyyy-MM-dd hh:mm:ss’) from dual;

求每个月月底:
其它函数:
round() 四舍五入
ceil(x) 取不小于x的最小整数
floor(x) 取不大于x的最大整数
substr() 取子字符串
concat() 连接多个字符串
concat_ws() 连接两个字符串(有分隔符)
split() 根据分隔符去拆分字符串
==下面我们用Hive运算一个wc的案例==
create table hive_wc(sentence string);
load data local inpath ‘/home/hadoop/data/hive_wc.txt’ into table hive_wc;

分开之后每一行变成了数组的形式。
现在已经把它们分隔开了,但是我们如果想要的结果是下面这样子:
hello
world
hello
hello
world
welcome
hello
==这属于行转列、列转行。(一个非常经典的面试题目)==
需要借助一个函数explode; select explode(split(sentence,”\t”)) from hive_wc;
select explode(split(sentence,”\t”)) from hive_wc;
再进行分组,count,就可以计算出wordcount了:
select word,count(1) from (select explode(split(sentence,”\t”)) as word from hive_wc)t group by word; select word, count(1) as count
select word, count(1) as count
from
(select explode(split(sentence, “\t”)) as word from hive_wc ) t
group by word
order by count desc;